Marcus Hutchins havde en skepsis om Mastodon og hvor meget det hele ville ende i et helvede af spam, bots og had.
Han trækker i land i sit indlæg I Was Wrong About Mastodon (escapingtech.com) – af årsager som en grundlæggende anden kultur og dynamikken, der opstår omkring accountability, når det er rigtige mennesker, der betaler og lægger kræfter i driften af en Mastodon-serverinstans.
Det tæller måske ikke 100% som self-hosting, når man lægger et system på en andens server. Men jeg har haft mit abonnement hos Gigahost i mange år nu og er generelt tilfreds med at køre med deres shared hosting. Inden da havde jeg en VPS, som… jeg ikke fik det fulde udbytte af, er nok den rette formuleringer.
Men en af mine favoritter er Baïkal-serveren. Den gør ting i baggrunden – skjult, men godt og meget værdifuldt. Serveren udstiller en kalender- og kontaktperson-tjeneste gennem CalDAV- og CardDAV-standarden. Det vil sige, at jeg kan bruge mine programmer og pege på den som stedet, der skal hentes kalender- og kontaktdata.
Mest af alt bruger jeg den på Android. Her har jeg DAVx5 til at synkronisere kalenderen, så jeg kan sætte min Baïkal-server som standardkalender på telefonen og tablet’en. Synkroniseringen er upåklagelig og virker, og dataene ligger hos mig – eller i hvert fald Gigahost. Det bliver i hvert fald ikke brugt til alle mulige formål, som jeg ikke kan stå inde for.
Jeg bruger en del tid på Powerpoints. Det er et fast element for en bureaukrat.
Sandheden er jo, at det meste i præsentations-transitioner er ligegyldigt og tilføjer ingen værdi. Når jeg har skullet bruge præsentationer, har jeg gjort det til en vane at eksportere dem til PDF. Og konklusionen er derfor, at præsentationerne i virkeligheden kunne laves på hvad som helst, og det er kun de manglende sideskift, der gør, at vi ikke laver det i Notepad eller Paint.
Men nok om Windows. Det er til arbejde.
Jeg har et svagt punkt for andre løsninger. Løsninger på standarder. Og her kommer der eksempler som Landslide. Det er Markdown. Det bliver til HTML eller PDF. Og det når frem ved hjælp af Python. Man laver sin Markdown-fil, kører den igennem Landslide og får en HTML-præsentation, som man så kan gemme, uploade eller hvad der nu passer. Se deres demo-præsentation.
Det er naturligvis ikke noget, jeg kan bruge professionelt på min hyper-fastlåste Windows-computer. Og så meget har jeg heller ikke brug for præsentationer i mit private liv, for ærligt talt, præsentationer tilføjer nærmest ingen værdi de fleste steder. Og man kan selvfølgelig bruge Impress, hvis man tager sin afhængighed med hjem. Men det er fedt, at man kan smide noget Markdown og lave det til, nå ja, lidt af hvert. Det er nok rester af mit Stockholm-syndrom fra dengang jeg legede meget med LaTeX og Beamer…
Dette her er en post til at undersøge, om Mastodon Autopost-plugin også virker fra WP-appen for Android.
Edit: Det gjorde den ikke. Det kunne jeg til gengæld forestille mig, at den gør, nu hvor jeg skriver fra webinterfacet og opdaterer posten i stedet.
Edit: Okay, den del virker.
Edit: Interessant. Den opdaterede post blev ikke postet på Mastodon. Der må være en validering på, om den allerede er afleveret/er en ny post med samme indhold som en tidligere.
Kloge Emilie Loiborg har skrevet om den nye AI-forordning på Radar –
Ekspert i digital forvaltning: Ny AI-forordning vil ramme bredt I denne analyse giver advokat hos Horten Emilie Loiborg, der har speciale i digital forvaltning og persondataret, en række bud på, hvilke vurderinger og krav EU’s kommende AI-forordning vil stille til myndigheder og virksomheder.
The Man Behind Mastodon Built It for This Moment: People fleeing Twitter have turned to Eugen Rochko’s alternative. He says social networks can support healthy debate—without any one person in control.
Det er jo blevet stadigt mere almindeligt at få sine nyheder og andre opdateringer gennem sociale medier. Men det er også blevet stadigt mere påtrængende med den grad, man er datahøstet – med mange forskellige formål.
Men det almindelige var jo tidligere noget helt andet – nemlig RSS – Really Simple Syndication. En standard, der er veldefineret – det er dybest set en XML-fil med en fast opmærkning, som fortæller om, hvad der er nyt – tidsstempler og links. Denne fil – en slags indeks, kan man sige – lægges online, så andre kan hente den, eksempelvis en gang i døgnet, en gang i timen eller hvad der nu passer. Det er også RSS, der ligger til grund for podcast-feeds. De enkelte feeds kan samles i en OPML-fil, som er den måde, jeg laver backups. Min egen er guld for en lille hyper-smal gruppe af folk, der har interesse for Linux, datasikkerhed og IT på beskæftigelsesområdet. En del CRM-systemer opretter automatisk et RSS-feed, ligesom WordPress har lavet et for denne side (hvilket er rart. I en fjern fortid håndskrev jeg dem, og det tager åndssvagt lang tid).
Men en forskel interessant for denne tid er, at det forærer væsentligt færre data om den person, der bruger det. Og derfor, selv om RSS er på retur, er det stadig på nogle områder overlegent – og har fortalere (her fra 2021).
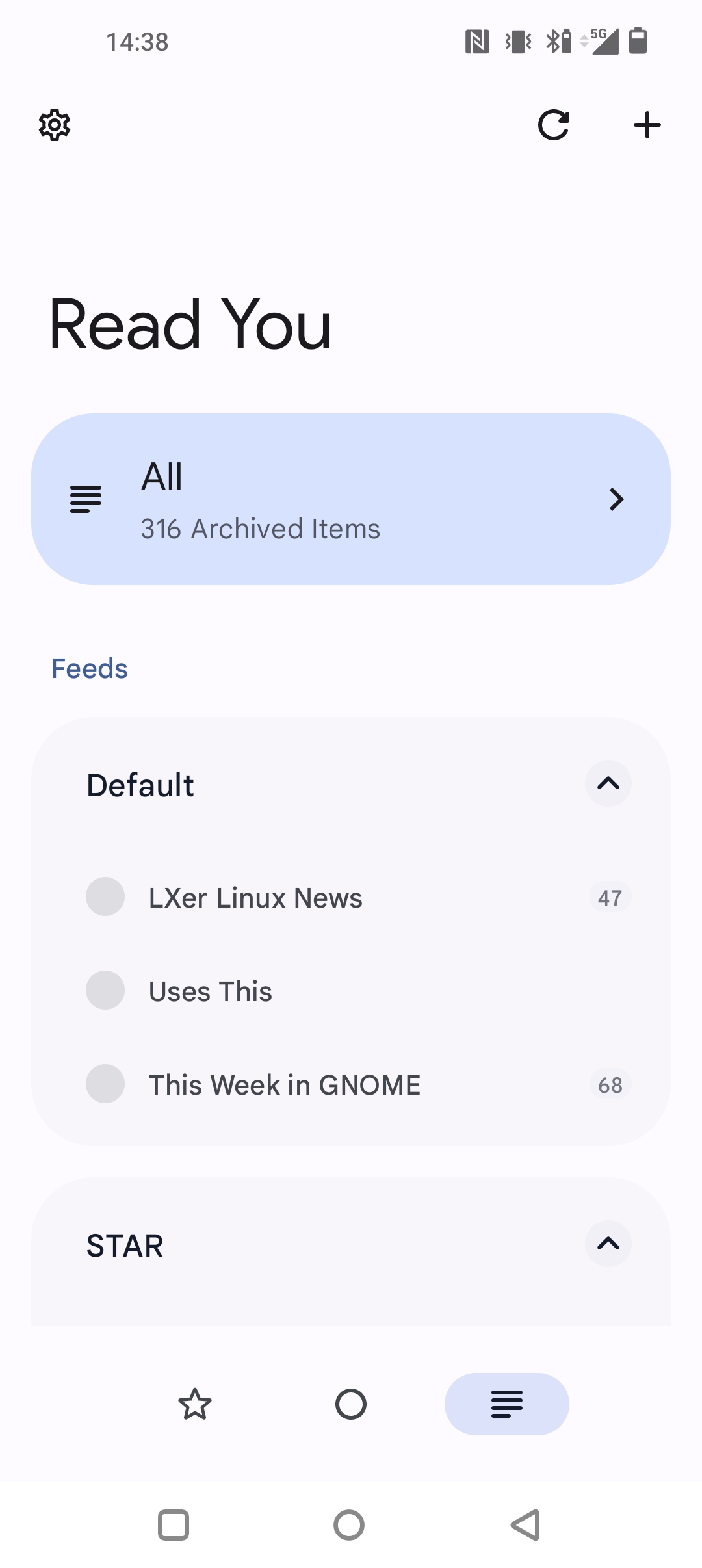
Jeg vil derfor ikke blot anbefale at kigge på RSS, men dertil anbefale Read You, som jeg bruger på Android, installeret fra Fdroid. Den er – hvilket udvikleren siger højt – inspireret af Reeder til IOS. Jeg synes, at designet er spartansk på den gode måde – ikke pyntet, men effektiv. Bemærk for eksempel, at man kan deaktivere notifikationer for det enkelte feed – jeg har notifikationer på dem, som har lav volumen, og hvor det er væsentligt for mit arbejde, men med andre – med stor volumen, som jeg gerne vil gennemse et par gange om ugen – har jeg ingen orientering om, når der er nye poster. Det gør det praktisk, at jeg får vist det, der er presserende, men jeg kan vente med at åbne postkassen på det andet, til jeg har tid.
Som nævnt ovenfor spiller RSS også en rolle i at levere podcasts – mere om podcast apps senere.
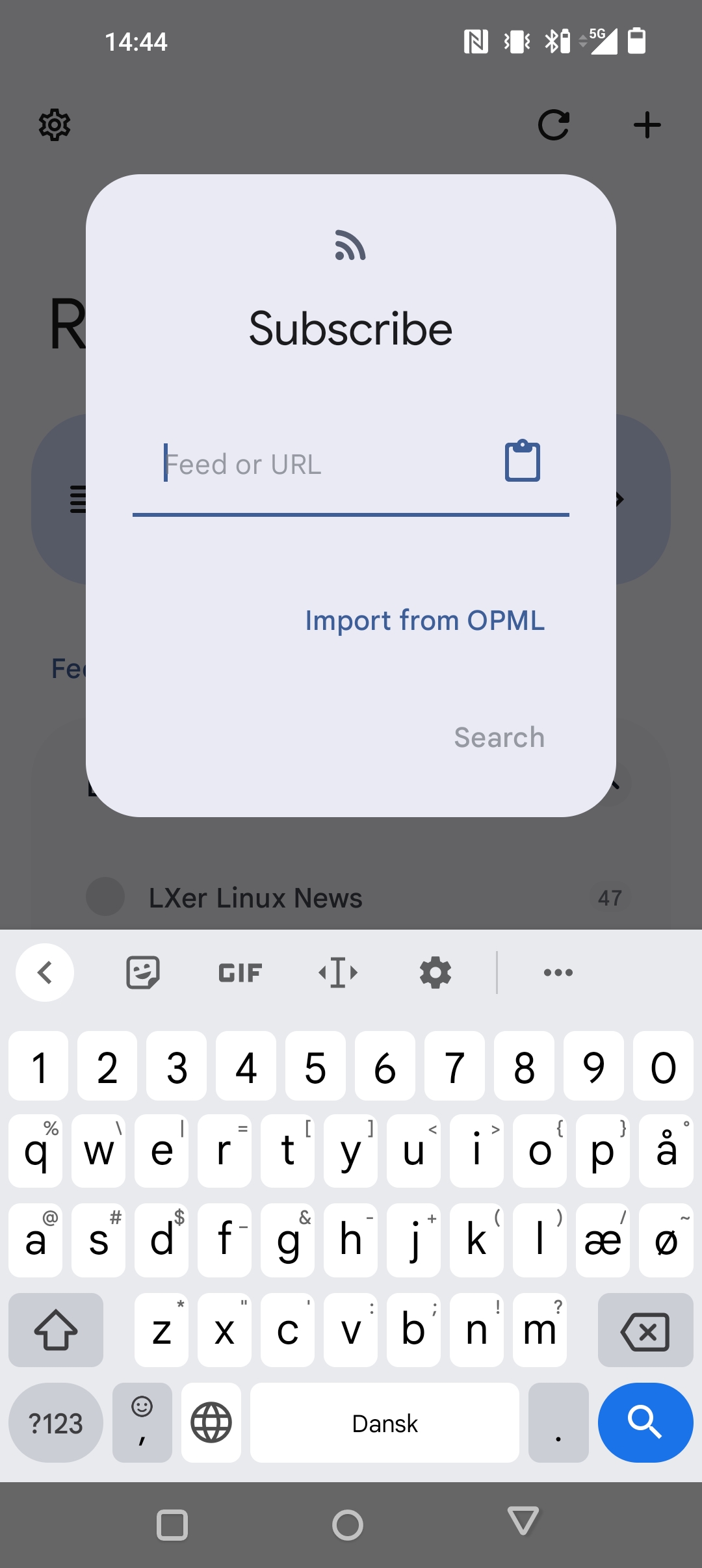
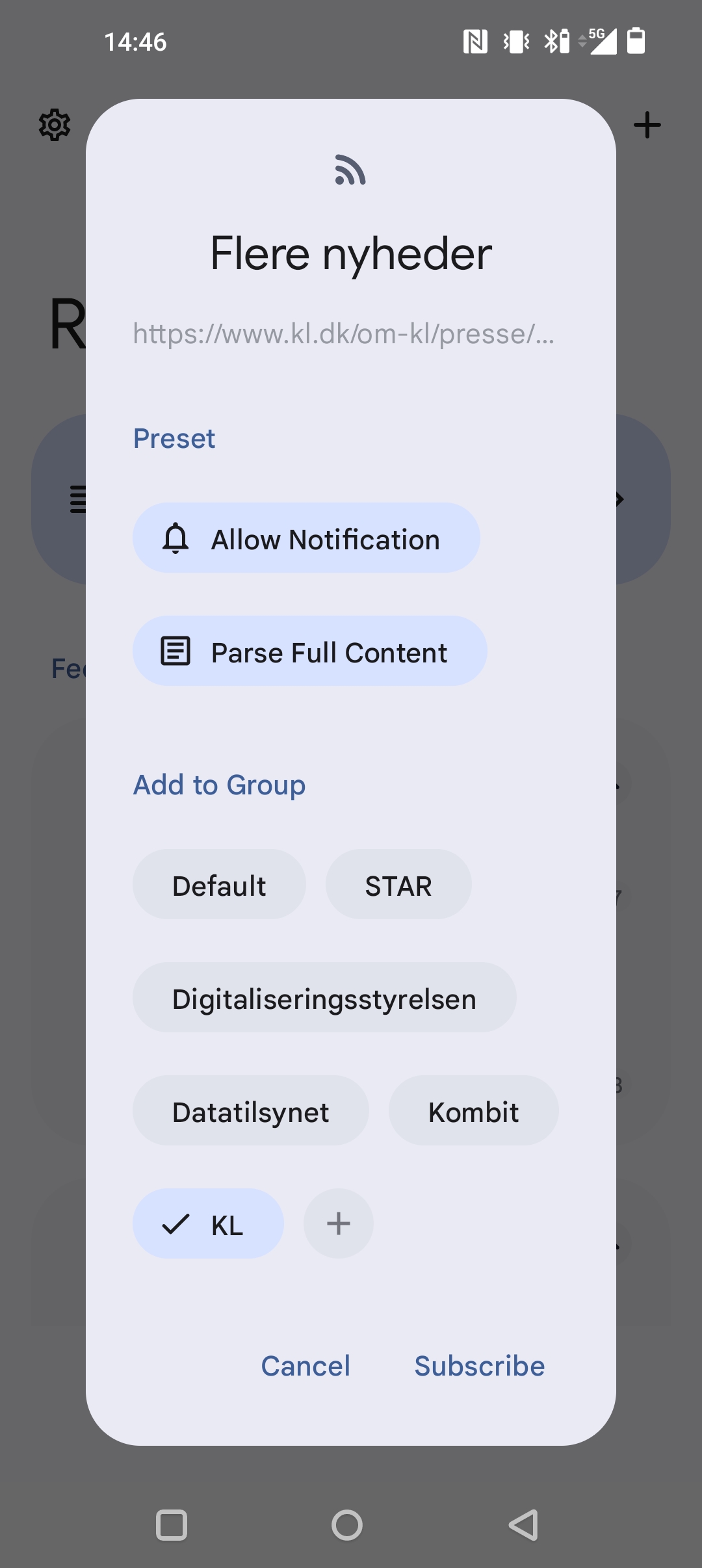
Forside – læste og ulæsteAbonner på et nyt feed ved at indsætte link eller importer en samling med OPMLTilføjelse/redigering af egenskaber for feedet.
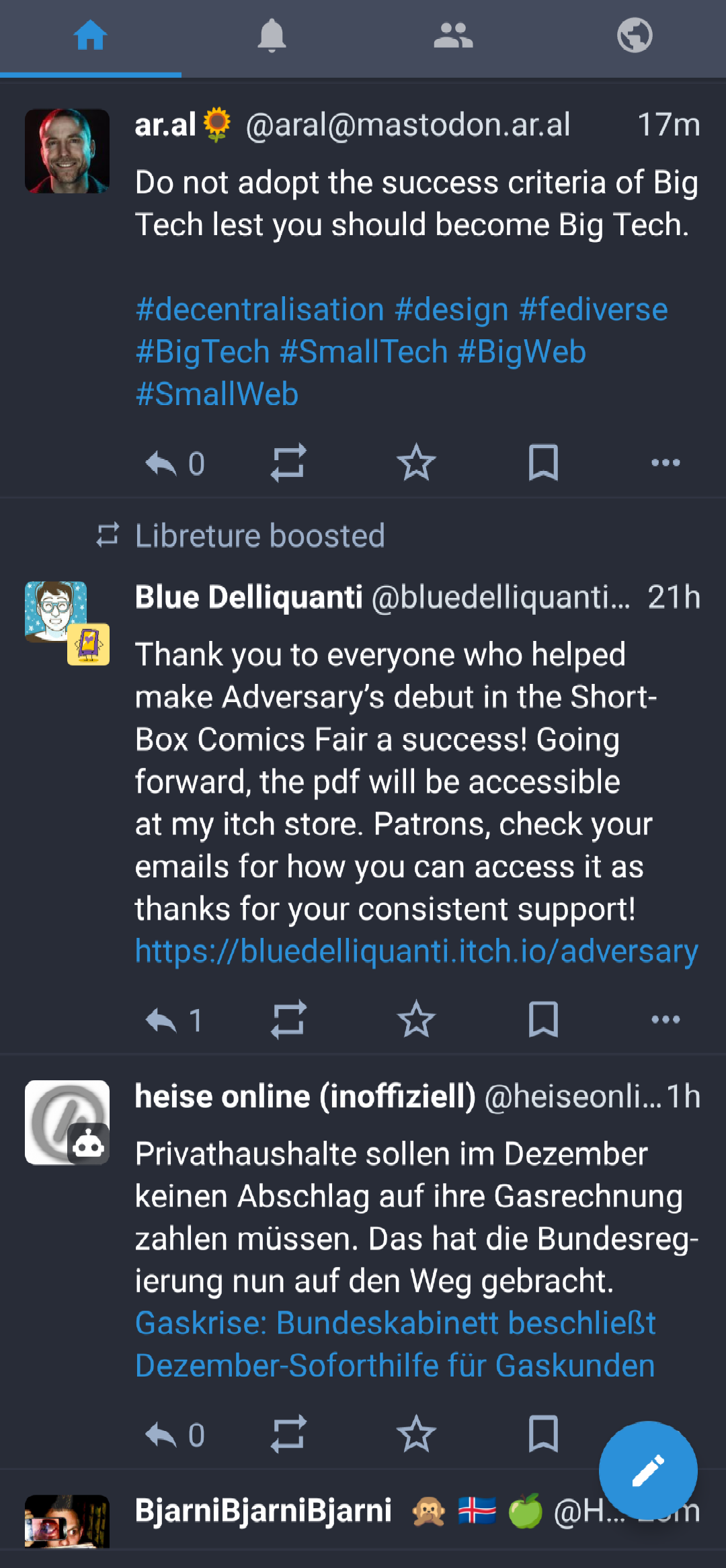
Nu skrev jeg om Mastodon – og den er rar at bruge i web-visningen, også i mobilvisningen. Men jeg bør også tilføje, at jeg er stor tilhænger af at bruge app’en Tusky på min lille Xperia – den gør virkelig brugerfladen væsentligt mere smidig at arbejde med.
Den almindelige oversigtNotifikationer på ting, man er tagget på eller med iOprettelse af ny meddelelse
Det er jo i forvejen nemt at dele ting mellem apps på Android, så man kan hurtigt sende ting til Tusky for en ny post.
Det er megen skepsis i disse tider om de store sociale medietjenester. Det er begyndt at blive synligt, hvor megen datahandel der faktisk sker.
(Indskud: Siden jeg begyndte at skrive dette indlæg i går, har Elon Musk lavet en større investering i Twitter, muligvis tvunget til det. Det er der meninger om, og det gør i hvert fald ikke indlægget mindre relevant)
Men der er alternativer til de store tjenester. I nogle tilfælde er det små tjenester, der gerne vil samme sted hen som de store, men der er også nogle tjenester, hvor det er flere aktive, men hvor de ligesom klikker ind i hinanden. Federated services, som man siger. Det er altså flere servere, det kører samme slags system, men som kan kommunikere sammen – lidt ligesom du godt kan få emails fra andre tjenester end den, du bruger.
Der er flere bud på dette – jeg har tidligere haft en konto på diasp.org, som var en server, der kørte Diaspora – en tjeneste, der var tænkt som et alternativ til Facebook og, som navnet antyder, var tænkt til dem, der var på flugt fra den. Jeg kunne godt lide at bruge Diaspora, og bortset fra alt det kommercielle, så tjente den meget de samme formål og funktioner som FB. Imidlertid var der ikke ret mange af mine bekendte, der var på Diaspora, så det begrænsede mulighederne – og et socialt netværk uden et netværk er ikke rigtigt socialt. Så det nåede ikke så langt. Systemet var fint, apps var okay, det hele var sådan set klart – det var bare en ret ensom affære.
Men i de senere år er der kommet fut under Mastodon. Den minder på mange måder meget om Twitter – kortere beskeder, medier, videoer – men igen kører den på en måde, hvor man kan køre sin egen server – én selv, ens firma, ens forening, hvad der nu måtte passe. De enkelte installationer kaldes instances, som jo nok tungt lader sig oversætte til instanser? Jeg har selv en konto på mstdn.io – https://mstdn.io/@mjjzf. Selv om jeg jo så overlader mine data til en tjeneste, så er den hele vejen tænkt til, at det ikke er enten-eller – at man kan hive sine data ud og importere andetsteds, hvis det giver mere mening:
Jeg følger jo så brugere fra en del forskellige instanser med en del forskellige tilgange – men jeg kan bruge min konto til at følge og skrive til dem på tværs. Og her kommer så en del af pointen: Der er faktisk rigtigt mange (for mig) rigtigt interessante brugere! Og mange at tale med, og mine opslag kommer lidt omkring, hvis de er interessante nok. Der er klart en følelse af, at som personligt socialt medie er det ret meget en fornøjelse. Eftersom der ikke er en reklamefinansiering og aggressive algoritmer, kan man så til gengæld overse ting, der blev postet udenfor det tidspunkt, hvor jeg er vågen – hvilket også gør, at hvis man ellers var på Twitter af marketing-hensyn, så er det en lidt sløj oplevelse. Men det kan man så glæde sig over, ikke mindst lige nu hvor der er den kedelige side af en valgfest på Twitter.
Mastodon fik i øvrigt kort opmærksomhed for at være den bagvedliggende platform for Trumps sociale medie med det nok misvisende navn Truth Social, omend det afstedkom en løftet pegefinger fra udvikleren for ikke at følge forpligtelserne i licensen. Det siger om ikke andet, at man kan lave et univers med de regler og den stil, man synes om. Der er også temaer som antifascistiske kooperativer og manga-entusiaster, hvis det er den retning, man trækker. Under alle omstændigheder kan man stadig blive koblet på med folk på tværs.
Jeg erhvervede mig for nylig – efter en række modeller fra OnePlus – en Sony Xperia 10 IV.
Den føles meget lille. Det var også meningen. Mine seneste telefoner føltes som fjernsyn. Min første tablet havde 7″ skærm – min foregående telefon var godt 6,5 – denne her er 6. Det burde ikke gøre en stor forskel, men det gør det. Den er smal. Jeg har altid ment, at der er en utappet business case for en Android-pendant til iPhone Mini. Den vejer også kun 160 gram, så med det ret lette cover jeg fik både fylder og vejer den noget mindre i lommen end sin forgænger.
Det var en anelse svært at få en fornemmelse af den ud fra anmeldelserne, som spændte fra begejstring til forfærdelse. Jeg tror, at jeg nu er med på, hvad anmelderne tænkte.
Mine behov er ret enkle. Jeg skriver beskeder og emails på den, bruger kalenderen, browser, lytter til musik og podcasts på Spotify, streaming af film og så videre. Det kan den indfri uden udfordringer. Det kører, som det skal.
Den er nemlig, og tilsyneladende ret bevidst, en mindre kraftig enhed med en lidt mindre skærm og dertil et temmeligt kraftigt batteri på 5.000 mAh. Så den er ikke helt så snappy som de andre enheder, jeg før har haft. Det tager lidt længere tid at tilslutte mine Bluetooth-enheder og lignende. Til gengæld har den – umiddelbart uden at anstrenge sig – mere end to døgns aktiv brug, før den behøver at blive opladet – hvilket så tager et stykke tid, fordi den ikke hurtigoplader som OnePlus-telefonen. Det får den så lov til henover natten. Så når anmelderne både ser meget at elske og bliver frustrerede over den, så kan jeg fuldstændigt se det.
Kameraet har den typiske Android-situation: Hardwaren virker udmærket, men softwaren er sløv. Så under lykkelige omstændigheder gode billeder…. Hvis folk bare vil stå stille.
Så jeg er ret tilfreds! Men jeg må jo også indrømme, at det er noget af et skift at gå ned til en enhed, der virker mindre responsiv end den foregående. Jeg fortryder ikke købet, og jeg må jo indrømme, at det føles en anelse magisk at have en telefon, der kan tage to døgn, inden den bliver træt. Min bedste nyere telefon var OnePlus 8, men den havde på sin bedste dag maksimalt halvdelen af Xperia’ens.